Feature Engineering: The Ultimate Power-Up or Just Meh?
One important step that data scientists and engineers go through when preprocessing data is feature engineering. During my first internship, I spent almost a month and a half on data cleaning. It was worth it, although the data was quite challenging. You might notice that I took a lot of time to clean the data, and that was mainly because I didn't know which methods to use to discover patterns and understand the relationships between my features before moving on to the machine learning part.
This experience made me appreciate these steps and their transformative impact on my AI model. Knowing the right methods for creating new features, reducing features, and understanding patterns is crucial for achieving the results you aim for. That's why today we will explore a few efficient methods for feature selection, creation, and understanding.
Feature Engineering
Feature engineering is typically the step that precedes model selection and training. After collecting, cleaning, and analyzing your data, you will focus on processing your features during this phase. This includes analyzing patterns and relationships, selecting the most relevant features, and creating new ones when possible.
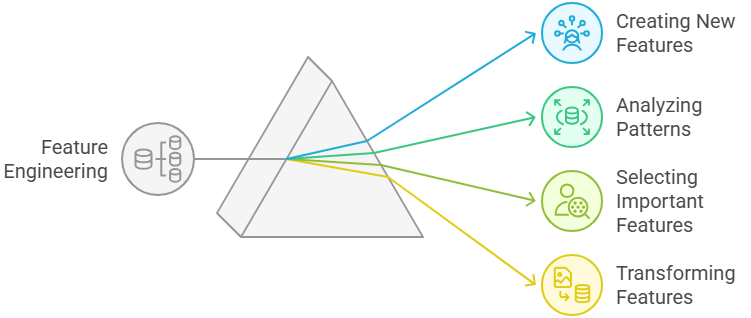
Features Engineering: Creating , Selecting, understanding
Now, we will explore methods for understanding features, creating new ones from existing data, and selecting the best features from the dataset:
- Understanding the features:Correlation,PCA,FCA,LDA.
- Creating new features:PCA.
- Selecting the features:RFE,AEFS,PCA.
Understanding the Features:
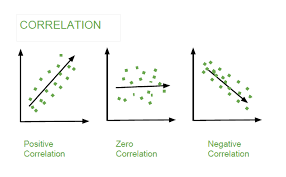
- Correlation:This method helps identify the strength and direction of the relationship between features. By calculating correlation coefficients, you can determine which features are positively or negatively correlated and how strongly they relate to each other. This insight can guide decisions on feature selection and engineering. However, it's essential to remember that correlation does not imply causation; just because two features are correlated does not mean that one causes the other.
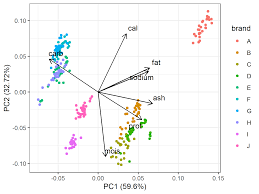
- PCA (Principal Component Analysis): PCA is a dimensionality reduction technique that transforms the original features into a new set of uncorrelated variables called principal components. It helps in understanding the variance in the data and the contribution of each feature to that variance, making it easier to visualize and interpret complex datasets.
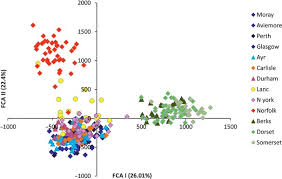
- FCA (Factor Correspondence Analysis):FCA is an exploratory technique used to analyze categorical data. It helps in understanding the relationships between categories and features by visualizing how different categories relate to one another. This understanding can inform feature selection and creation.
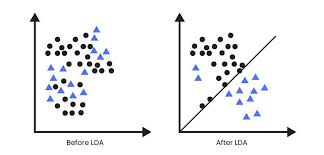
- LDA (Linear Discriminant Analysis): LDA is a supervised technique that focuses on maximizing class separability. It transforms features to emphasize differences between classes, allowing you to understand which features are most effective in distinguishing between categories.
Creating New Features:
- PCA (Principal Component Analysis):In addition to understanding features, PCA can be used to create new features. By combining existing features into principal components, PCA generates new dimensions that capture the most significant variance in the data. These new features can improve model performance by reducing noise and redundancy.
Selecting the Features:
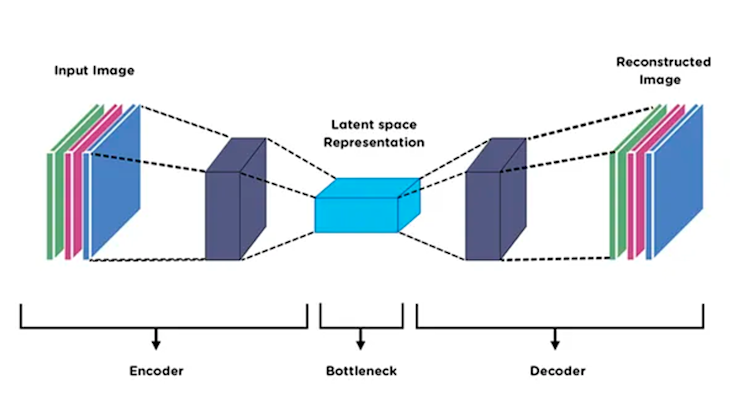
- AEFS (Autoencoder-based Feature Selection):AEFS utilizes deep learning techniques to identify important features. By training an autoencoder, which learns to compress and reconstruct the data, AEFS can highlight which features are most relevant for capturing the underlying patterns in the data.
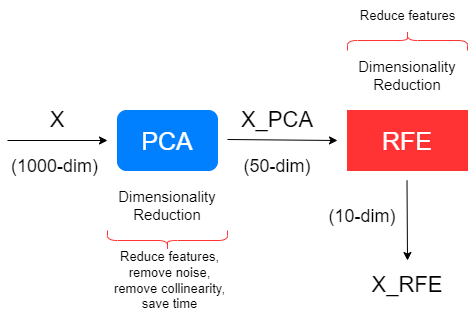
- RFE (Recursive Feature Elimination): RFE is a feature selection method that recursively removes the least important features based on a chosen model's performance. By iteratively refining the feature set, RFE helps identify the most relevant features that contribute to the model's predictive power.
- PCA (Principal Component Analysis): PCA can also serve as a feature selection method by reducing dimensionality. By selecting the most significant principal components that explain the majority of the variance, you effectively select a subset of the original features while retaining essential information.
Methods Overview
| Method | Type | Purpose | Input | Mathematical Basis | Output |
|---|---|---|---|---|---|
| PCA (Principal Component Analysis) | Unsupervised | Finds directions (principal components) that maximize variance in the data. | Numerical data | Eigen decomposition | Principal components |
| LDA (Linear Discriminant Analysis) | Supervised | Finds a linear combination of features that best separates two or more classes. | Labeled numerical data | Scatter matrix analysis | Discriminant functions |
| FCA (Factor Correspondence Analysis) | Exploratory | Detects associations and relationships among categorical variables. | Categorical data | Singular Value Decomposition | Factor maps |
| RFE (Recursive Feature Elimination) | Supervised | Iteratively removes the least important features based on a model's performance. | Numerical/categorical data (depending on the model used) | Recursive elimination via machine learning models | Ranked feature importance |
| AEFS (Autoencoder-based Feature Selection) | Unsupervised/Semi-supervised | Uses autoencoders to learn a compressed representation of the data, identifying relevant features. | Any structured numerical data | Neural network optimization | Selected feature set based on the autoencoder's bottleneck layer |
Summary Table
To help you choose the right method for feature engineering, we provide a summary of each approach and its appropriate use case.
| Method | Feature Engineering | Feature Selection | Feature Creation | Feature Understanding |
|---|---|---|---|---|
| PCA | Yes | Yes | Yes | Yes |
| LDA | - | - | - | Yes |
| FCA | Yes | - | Yes | Yes |
| RFE | - | Yes | - | - |
| AEFS | Yes | Yes | Yes | Yes |
Conclusion
There are many methods available to help you engineer your features effectively. However, the key is knowing when and how to use them correctly. Thank you for reading the full article—I hope you found it useful! If you know of more efficient methods that deserve priority in this discussion, feel free to share them.